
Nachdem das Archiv nun eingerichtet ist, kann das Befüllen mit Schriftstücken beginnen. Für das Scannen und die Klassifikation steht die Anwendung ecoICE zur Verfügung. Als Scanner können alle Geräte verwendet werden, die über TWAIN, WIA oder ISIS angebunden werden. Im Normalfall sollte die TWAIN Schnittstelle verwendet werden, da hier die für den jeweiligen Scanner vom Hersteller gelieferte Software zum Einsatz kommen kann.
Wir haben für das Scannen unserer täglichen Post ein Multifunktionsgerät mit Flachbettscanner im Haus. Für das Scannen unserer alten Akten konnten wir uns zum Glück einen Einzugsscanner (Kodak i1220) ausleihen, da wir eine große Menge an Akten zum Scannen hatten. Ohne Einzugsscanner ist das Scannen von großen Aktenmengen nicht in realistischer Zeit schaffbar.

Benutzerhandbuch ecoDMS Image Correction Editor
Beim ersten Start sollte man im Menü „Datei“ unter dem Punkt „Scannen…“ den Menüpunkt „Scanner wählen…“ aufrufen und seinen Scanner auswählen. An den anderen Einstellungen sollte man nur etwas ändern nachdem man sich das Benutzerhandbuch gut durchgelesen hat.
Scannereinstellungen
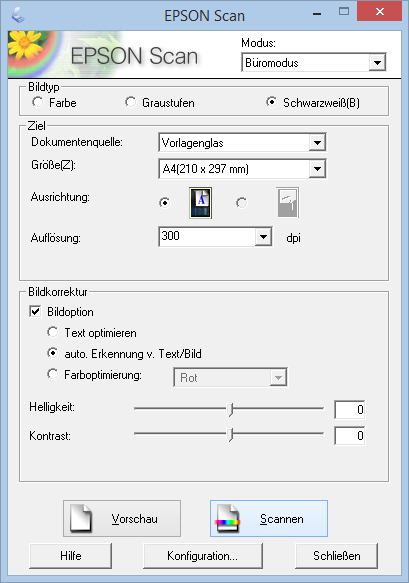
Die richtigen Scannereinstellungen für den jeweiligen Scanner zu finden ist immer etwas schwer. In der Regel bracht ecoDMS aber gewisse Einstellungen damit die OCR später ordentliche Ergebnisse liefert.
- 200 – 300 dpi
- SchwarzWeiss
- Bildverbesserung
- Bild geraderichten
- Bild beschneiden
Die meisten Flachbettscanner oder Multifunktionsgeräte bieten nicht sehr viele Einstellungsmöglichkeiten an. Gerade die Bildverbesserungen sind meistens den besseren Flachbett- oder Einzugsscannern vorbehalten. Bei unseren Gerät lässt sich nur die Auflösung und die Bildfarbe einstellen.
Scannen
Das Scannen eines neuen Dokumentes kann im ecoICE mit dem Knopf
![]()
gestartet werden. Im Falle unseres Flachbettscanners öffnet sich dann der TWAIN Dialog unseres Scanners.
Bei einem Flachbettscanner wird pro Scanvorgang nur 1 Seite gescannt. Um einem Dokument eine weitere Seite hinzuzufügen, kann man einen weiteren Scanvorgang über den Button
![]()
auslösen. So können Dokumente mit beliebig vielen Seiten schnell und einfach eingescannt werden. Bevor man das so gescannte Dokument allerdings klassifizieren kann, muss man das Dokument erst über den Button
![]()
gespeichert werden.
Klassifikation
Nach dem Scannen und vor dem Archivieren kommt noch die Klassifikation des gescannten Dokumentes. Die Klassifikation dient dazu das Dokument mit für die Ablage und den schnellen Zugriff wichtigen Information zu versehen. Hier sind bei ecoDMS nur wenige Informationen nötig, da die Dokumente später per OCR mit einem durchsuchbaren Volltext hinterlegt werden.
In der Grundinstallation werden folgende Felder in der Klassifikation angeboten:
- DocId (wird vom System vergeben)
- Hauptordner
- Bemerkung
- Status
- Ordner
- Dokumentenart
- Datum
- Wiedervorlage
Die Felder Hauptordner und Ordner werden für die Ablage des Dokumentes im Archiv benötigt und speisen sich aus der im ecoDMS Client eingerichteten Ordnerstruktur. Das Feld Status gibt den Bearbeitungsstatus des Dokumentes an. Im Feld Bemerkung sollte am kurz und knapp erfassen um was es sich bei dem jeweiligen Dokument handelt. Das Feld Dokumentenart enthält alle im ecoDMS Client eingerichtete Dokumentenarten. Das Feld Datum sollte mit dem Eingangsdatum des Dokumentes versehen werden, das Tagesdatum des Scannens sollte nur im Ausnahmefall verwendet werden. Über das Feld Wiedervorlage kann eine Wiedervorlage des gescannten Dokumentes eingerichtet werden. Die Wiedervorlage wird später im ecoDMS Client angezeigt.
Der Bereich um die Klassifikation bietet einige Einstellungsmöglichkeiten in Bezug auf eine Vorbelegung der Klassifizierungsfelder. Besonders das Festlegen der Standardwerte kann sehr gut genutzt werden, wenn man mehrere gleichartige Dokumente klassifizieren muss. In der Vollversion kann man hier auch mit Vorlagen arbeiten, in der Community-Version steht aber leider nur 1 zur Verfügung.
Als hilfreich hat sich auch das Ausblenden von Feldern, die man nicht verwenden möchte, erwiesen. Das schafft Übersicht und macht die Klassifikation einfacher. Bei Bedarf können auch zusätzliche Ordner und Dokumentenarten in der Klassifikation erfasst werden.
ecoDMS PDF/a Drucker
Über den ecoDMS PDF/a Drucker lassen sich Dokumente direkt ins Archiv drucken. Diese Funktion kann genutzt werden um z.B. Webseiten oder eMails im ecoDMS zu archivieren. Der Drucker kann aus jedem Programm ganz einfach über die jeweilige Druckfunktion aufgerufen werden. Das Dokument wird zuerst gedruckt und dann direkt in PDF/a gewandelt. Nach der Wandlung öffnet sich ein Klassifikationsdialog analog zum Klassifikationsbereich des ecoICE, in dem alle benötigten Klassifikationsfelder gefüllt werden können. Nach dem Archivieren wird das Dokument dann im PDF Viewer der Wahl geöffnet.
Dokumentenimport aus dem Dateisystem
Ein weiterer sehr interessanter Weg Dokumente zu archivieren, ist der Import aus dem Dateisystem. Bei der Installation des ecoDMS Servers wird im Arbeitsverzeichnis des Servers ein Ordner scaninput angelegt. In diesen Ordner können Dateien im PDF oder TIFF Format eingestellt werden, die dann direkt vom Server verarbeitet und dem ecoICE zur Klassifikation zur Verfügung gestellt werden. Da viele Webseiten heute Rechnung und andere Dokumente im PDF Format zum Download anbieten, bietet sich dieser Weg für diese Dokumente geradezu an. Wir nutzen den scaniput Ordner, in Form einer Freigabe auf unserem Windows Homeserver, für den Import von PDF Dateien die wir per eMail oder Webseite zur Verfügung gestellt bekommen. Besonders Rechnungen und Onlinekontoauszuüge lassen sich so schnell und einfach ins Archiv überführen.
Fazit Scannen und Klassifikation
Das Scannen und Klassifizieren geht mit dem ecoDMS Image Correction Editor gut von der Hand. Das Scannen mit einem Flachbettscanner ist gut gelöst und auch für einen Laien einfach durchzuführen. Für größere Dokumentenmengen sollte man allerdings auf einen Einzugsscanner zurückgreifen, da das Scannen sonst sehr viel Zeit in Anspruch nimmt. Wir haben durch die Ablösung unserer Papierordner ca. 1500 Dokumente zusammenbekommen und sind sehr froh das ganze mit einem Einzugsscanner gemacht zu haben. Wobei das Aufbereiten des Papieres mit den Trennblättern sehr aufreibend ist (Wir haben die Trennblätter wiederverwendet).
Der PDF/a Drucker und der Import aus dem Dateisystem runden das ganze sehr gut ab und man spart sich lästiges ausdrucken und einscannen.
<< Teil 2 – Einrichtung des Archives | Teil 4 – Arbeiten mit dem Archiv >>
Hi, ich bekomme leider den Scaninput Ordner nicht zum laufen. Kannst du mir da weiterhelfen? Die PDFs werden zwar vom EcoDMS Server gelöscht, erscheinen aber nicht in der Oberfläche. Hast du eine Idee oder hattest du auch Probleme bei der Einrichtung dieses Ordners?
Bei mir funktioniert der Ordner wunderbar. Ich hatte allerdings einige Probleme den Ordner sinnvoll im Netzwerk freizugeben. Die Dokumente aus dem Ordner erscheinen bei mir nach dem Import im ecoICE – Image Correction Editor zur Klassifikation. Verschwinden die Dokumente bei dir vollständig? Kann es sein das dein Benutzer keine Berechtigungen für Dokumente aus dem ScanInput-Ordner hat?
Vielen Dank! Das war der richtige Tip. Ich musste mir noch den ecoICE installieren. Darin sind alle Dokumente 🙂
Freut mich das ich helfen konnte 🙂 Das es so einfach wird habe ich allerdings auch nicht gedacht. Über den ecoICE kann man auch direkt mit einem Scanner die Dokumente erfassen und klassifizieren. Wobei der Import über den ScanInput Ordner in den meisten Fällen besser ist, da dort die OCR schon vor der Klassifikation drüber läuft.
Hallo Zusammen
Ich brauche Eure Hilfe bezüglich Regex. Ich habe ein neues ecoDMS System und sollte dort den Rechnungsbetrag einlesen können.
Mit der Deutschen Schreibweise der Zahlen funktioniert dies aber leider mit der Schweizer Variante nicht.
Deutschland = 1.234,12 Thausender sind punkte und Decimal ist ein Komma
Dies ist der Code vom Hersteller
REGEX:(?<=Nettosumme:)([\s]*)\d{1,8}([\.,]\d{2})
Was ich brauche ist aber:
Schweizer = 1'234.15 Thausender sind Apostrofe und Decimal ist ein Punkt
Nettosumme: = 1'234.15
1'234.15
-1'234.15
Also Auslesen Wenn Nettosumme steht mit dem Betrag das den Betrag auslesen.
Wäre sehr dankbar wenn mir das jemand helfen könnte und mir das vielleicht ein kurz beschreiben könnte
Habe eben schon vieles Probiert auf alle arten und kriege es nicht hin.
Danke Euch
und Happy New Year
Dany
Hey Dany,
erstmal der Vollständigkeit halber, das würde so (REGEX:(?<=Nettosumme:)([\s]*)\d{1,8}([\.,]\d{2})) nicht funktionieren.
Korrekt wäre: REGEX:(?<=Nettosumme:)([\s]*)((((\d+)[,.]{1,10})+\d{0,2})|(\d+(?!,)))
Beispiel-String: Nettosumme:34.5254,44
Für Schweizer Franken würde z.B. funktionieren: REGEX:(?<=CHF:)([\s]*)((((\d+)['.]{1,10})+\d{0,2})|(\d+(?!.)))
Beispiel-String: CHF:111'146.90
Ich werde das mal in meinem Artikel unter https://www.simon42.com/regex-in-vorlagen-von-ecodms-verwenden/ mit aufnehmen 😉
Hallo Familie Kröpelin,
ich möchte unsere Kontoauszüge (6 Konten bei der gleichen Bank, gleicher Dokumentenaufbau) möglichst mit einer Klassifizierungsvorlage den kontenbezogenen Unterordnern zuordnen. Die Kontobezeichnung kann ich aus den PDF-Dokumenten auslesen (Feld in der Formularvorlage „Kontoauszug“). Ich weiss allerdings nicht, wie ich anhand der ausgewiesenen Kontonummer ecoDMS veranlassen kann, das Dokument dem passenden Unterordner zuzuweisen, ohne gleich 6 Klassifizierungsvorlagen zu schreiben. Gibt es hier einen Weg? Für einen Lösungsvorschlag wäre ich sehr dankbar!
Beste Grüße Martin H